aws - S3 Life cycle
1. S3 Storage Class
S3는 모든데이터를 물리적으로 동일한 스펙인 곳에 저장 할 수도 있지만, 경우에 따라 다른 곳에 저장 할 수도 있다. 이렇게 저장되는 디스크의 스팩을 여러개로 나눠서 구분하고, 이를 S3 storage class 라고 한다.
쉽게 말하면 자주 쓰는것(게임)은 ssd에 저장하고 잘 안쓰는 데이터는 그냥 하드 디스크에 저장해서 관리하여 비용 측면에서 더욱 저렴하게 관리 할 수도 있다는 말이다.
제공해주는 class 종류는 많은데 결국엔 최근 쓰여진 파일은 많이 읽기/쓰기가 많으니까 좋은곳에 두고, 오래된 파일들은 어차피 자주 안보고 보존or가끔 볼때가 목적인 경우가 많으니까 어디 구석에 두자는 말이다. 물론 이런 class일 수록 비용은 더 저렴하다.

참고로 일반적으로 사용되는 class는 Standard class이다. 각 클래스 마다 장단점은 있지만 눈에 띄는 class만 적어보자면
1. S3 Zone-IA
이름처럼 하나의 az에 데이터를 저장하기 때문에 해당 az가 물리적으로 날라가면 데이터가 그냥 날라간다
2. S3 Glacier Flexible Retrieval, S3 Glacier Deep Archive
다른 storage는 생각보다 standard 클래스랑 처리량 스펙이 똑같은데 이 두 class는 지연시간이 길 수도 있다. 또한 검색한 gb당 요금이 책정되는 점도 특징이다.
1.1 각 테이블 별 비용 및 스펙
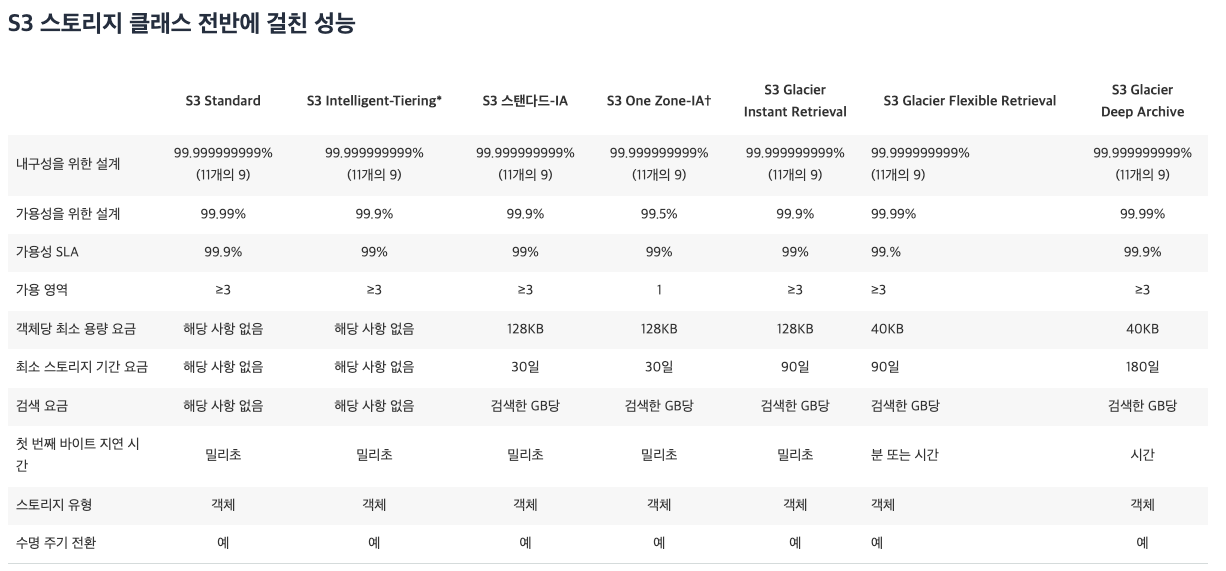
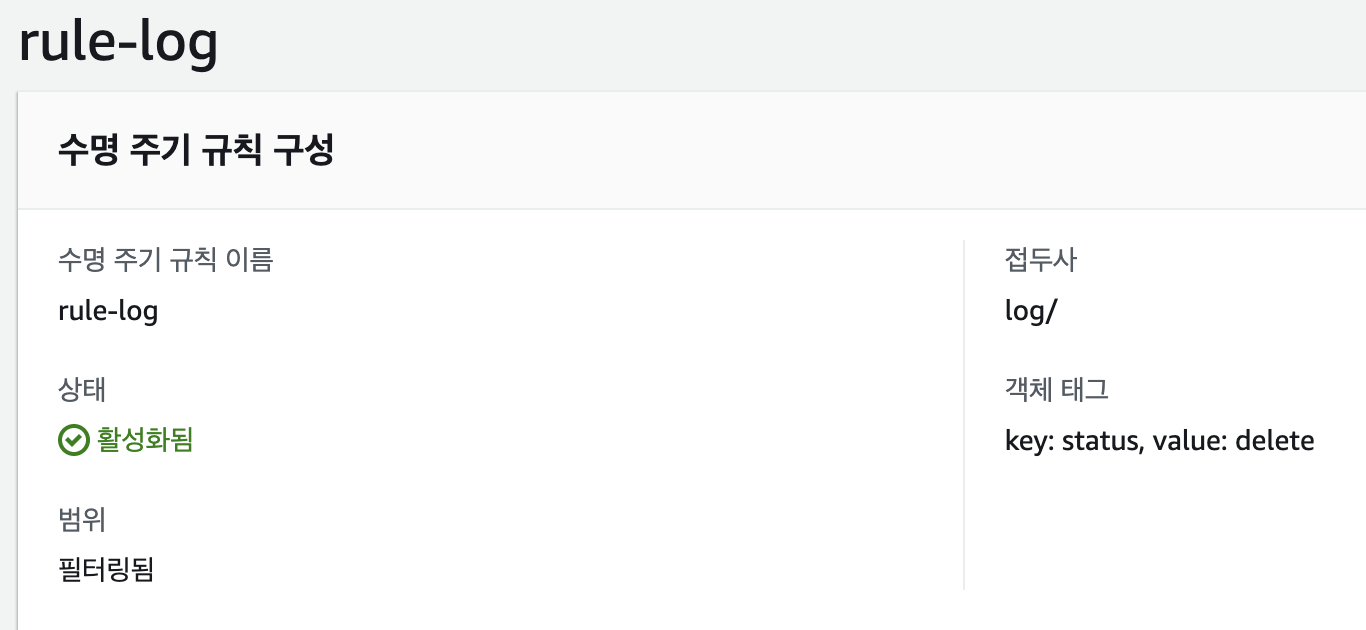
이렇게 데이터에 따라 특정 규칙을 정하고 어느 class로 보낼지 정할 수가 있고, 아니면 아예 삭제 해버릴수도 있는데 이러한 기능을 lifecycle rule(수명주기 규칙)이라고 한다.
aws 사이트에서 s3 → 버킷 선택 → 수명주기 구성 을 보면 해당 규칙을 확인 할 수가 있다.
1.2 수명 주기 규칙 구성
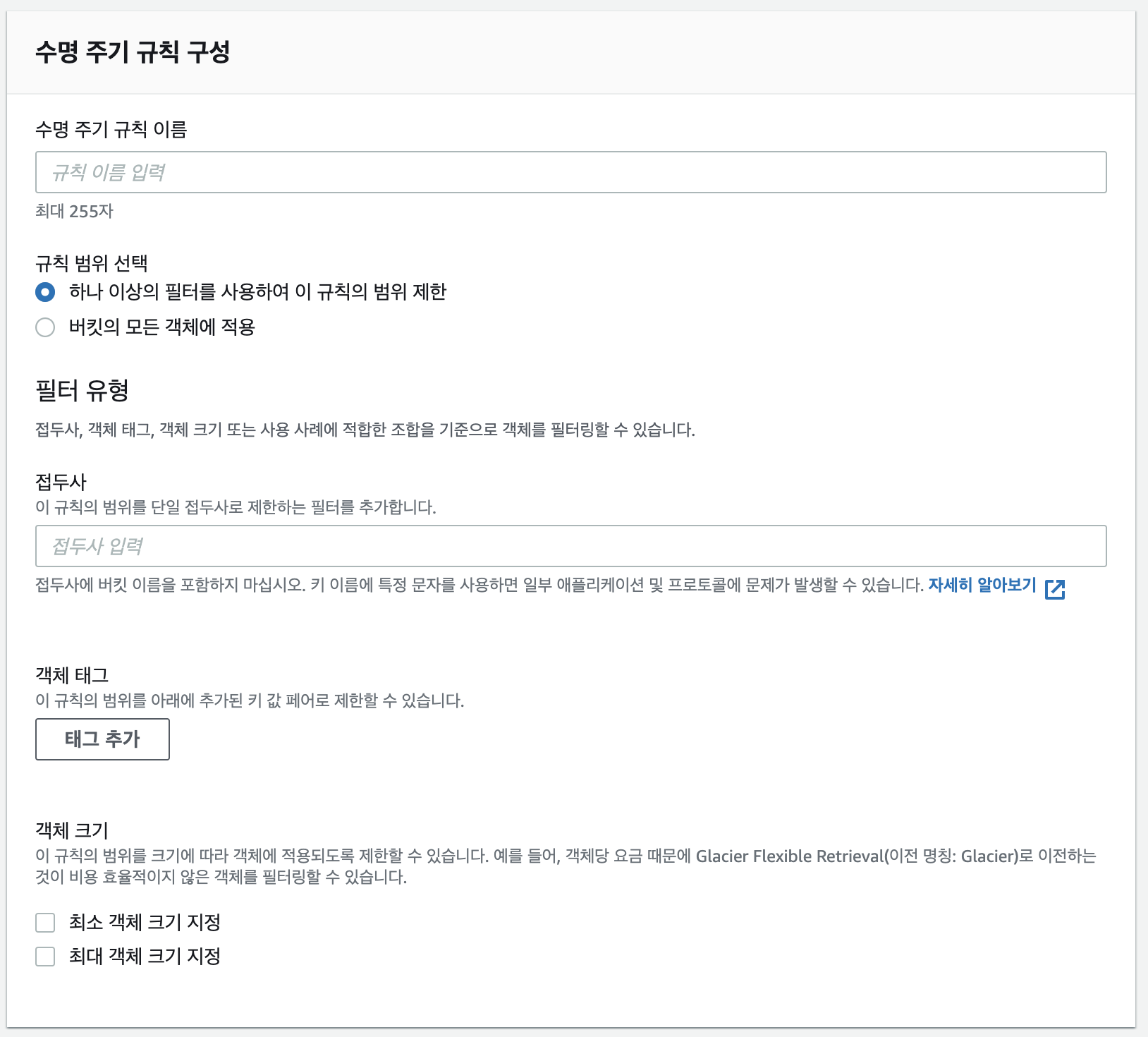
수명 주기 규칙 이름은 그냥 구분용 이름이고, 규칙 범위 선택 을 통해 대상을 지정할 수 있다. 대상 지정은 특정 디렉토리 하위를 지정(접두사)하거나 객체가 가지고 있는 tag를 기준으로 그 대상을 특정 할수가 있다.
참고로 s3파일 삭제를 이런 수명 주기를 이용해서 삭제하면 좋은점이 혹시나 삭제 대상이 많아도 일단 tag만 붙여 준 뒤, tag가 붙은 후 시간이 지나면 삭제되게 처리하면 삭제 처리 시간도 빠르고 혹시나마 복구를 해야한다면 빠르게 복구 할 수도 있다.
1.2 수명 주기 규칙 작업
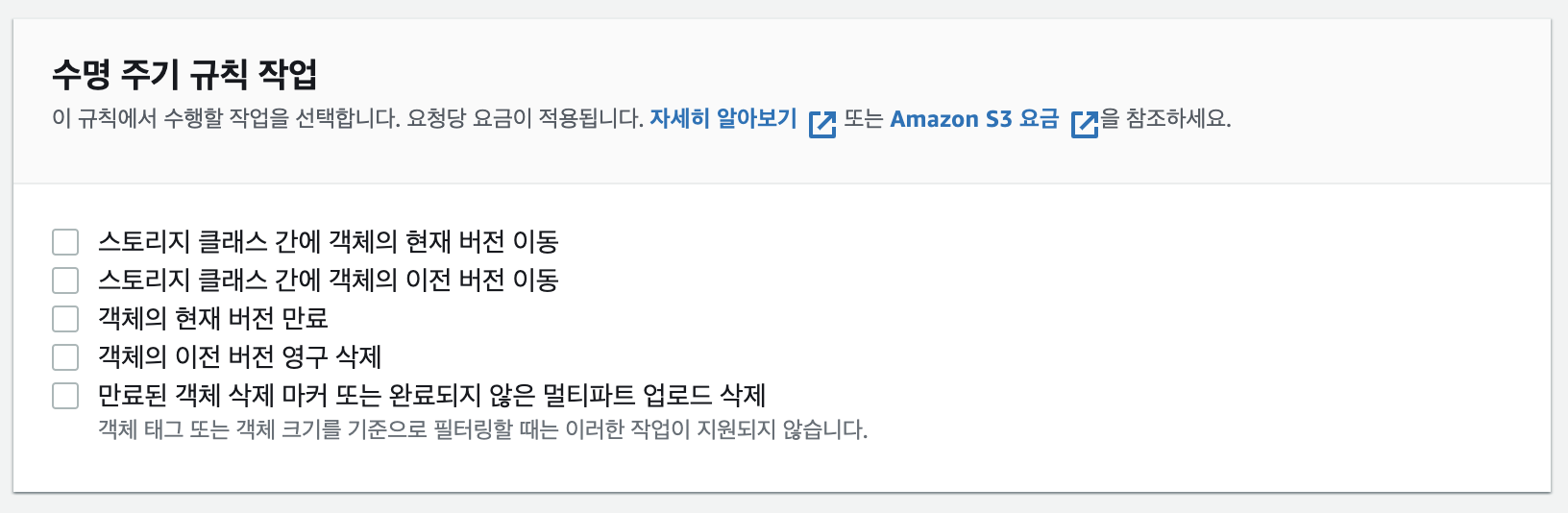
위에서 대상을 지정했다면, 여기서 파일을 진짜 어떻게 처리할지 셋팅하게 된다. 앞서 말한대로 생성 후, 지정된 날짜가 지나면 storage class를 옮겨버리거나(위의 2개 작업) 물리적으로 삭제 처리 되도록 지정(3,4번째꺼) 할 수도 있다.
버전이라는 말도 나오는데, 그냥s3 객체 버전 관리를 말하는거다.
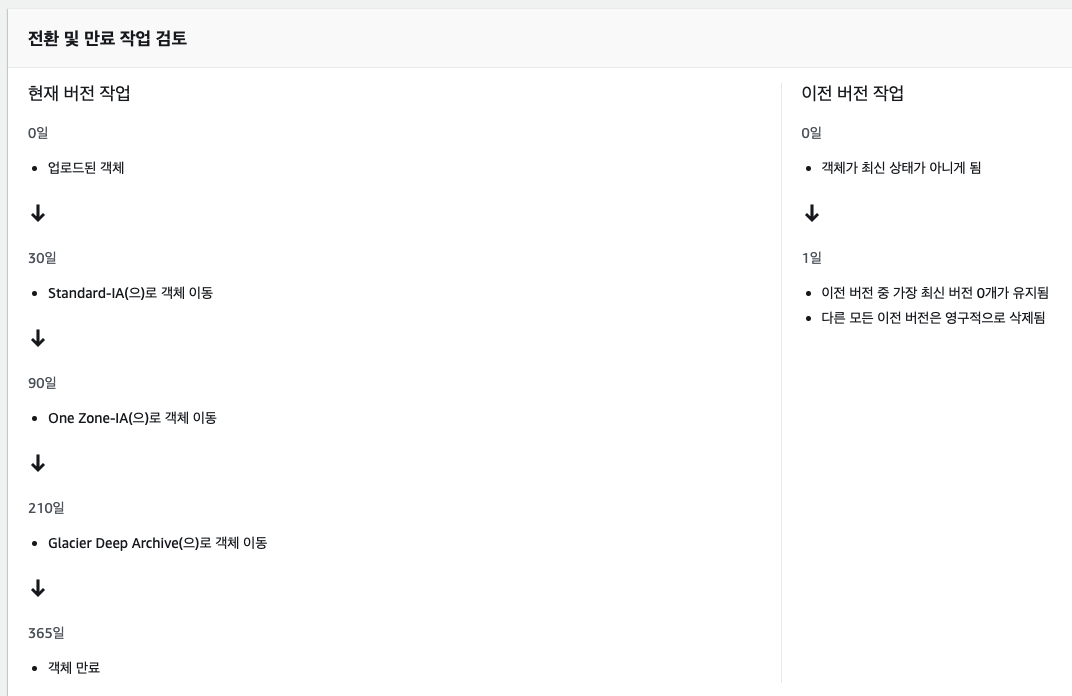
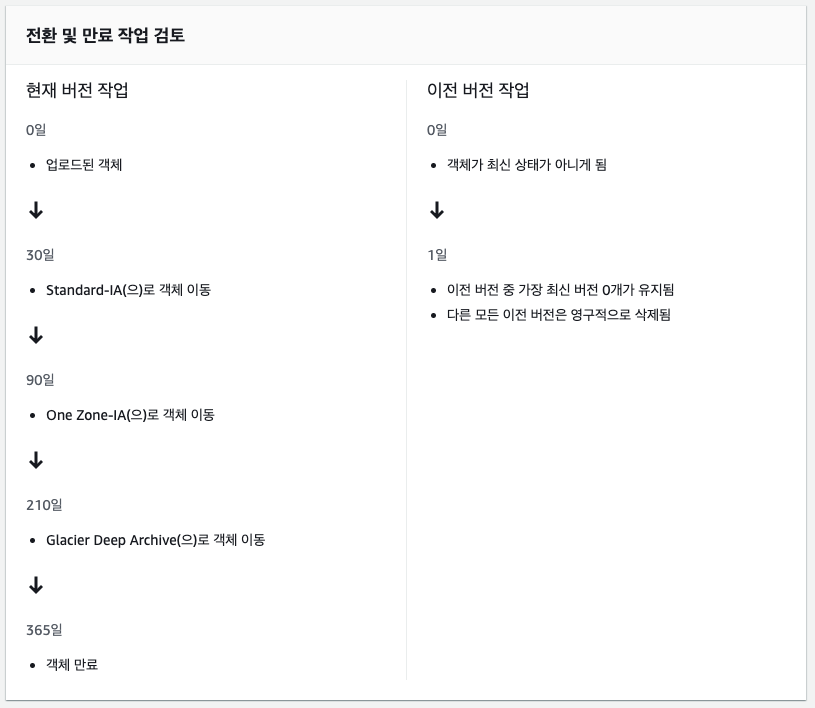 이런식으로 클릭클릭 하면서 셋팅해 나아가면 최종적으로 생성일을 기준으로 데이터 라이프 사이클을 확인 할 수가 있다
이런식으로 클릭클릭 하면서 셋팅해 나아가면 최종적으로 생성일을 기준으로 데이터 라이프 사이클을 확인 할 수가 있다
위 이미지는 특정 날짜가 지나면 class를 계속 옮기다가 최종적으로 영구 삭제 처리 되도록 설정한 내용이다
2. terraform으로 구현
전체 소스는 개인 git repository에 올려놨고, 몇가지 옵션 설명을 하자면 아래와 같다
2.1 aws_s3_bucket_public_acces_block
별다른 설정없이 만들면 s3에 올려진 파일들은 외부에서 접근이 가능하다. 그냥 테스트 용도긴 하지만 이런거 굉장히 불편해서 다 block 되게 막아놓기 위해 설정 해놨다
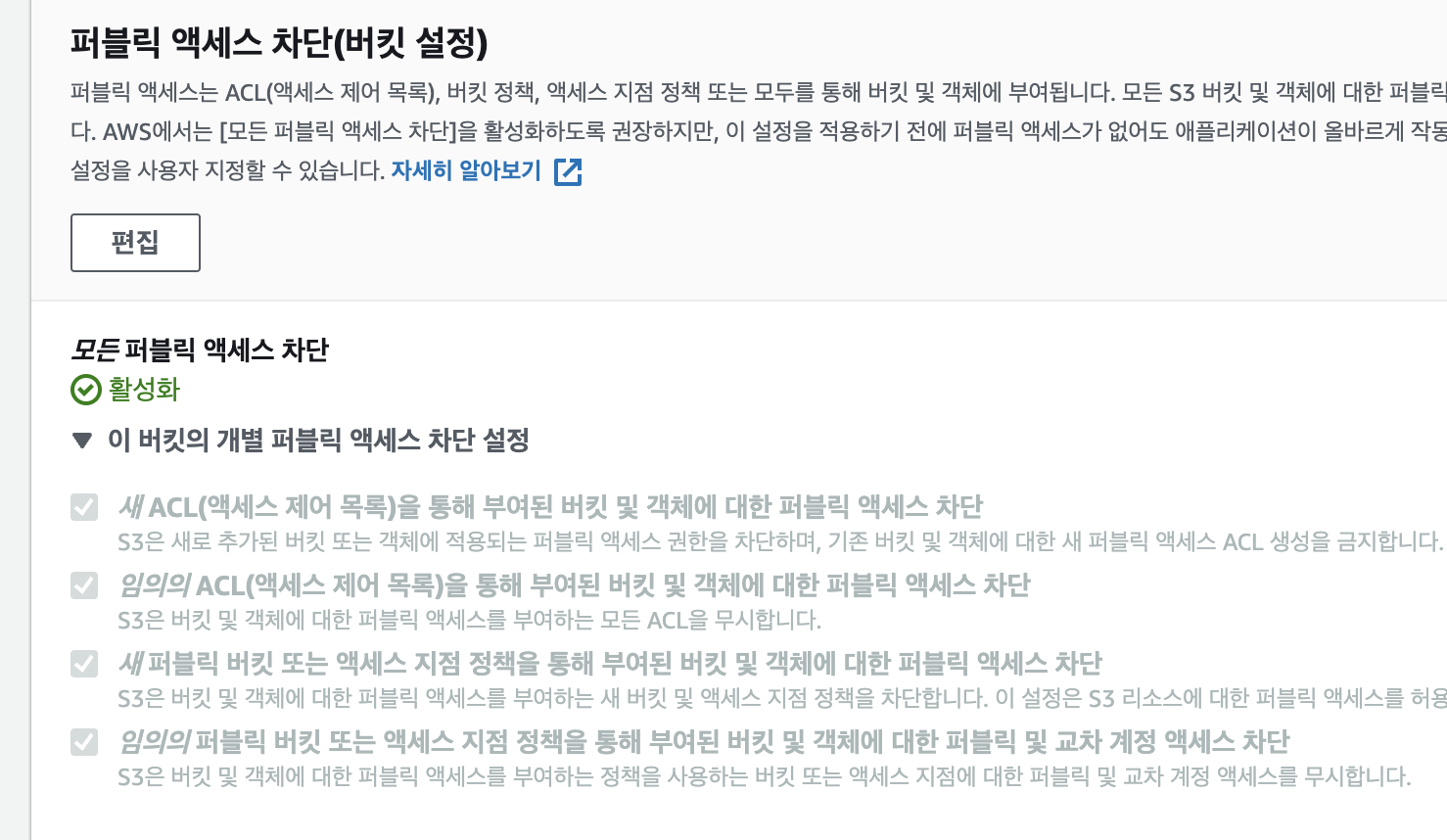
웹에서 보면 위와 같은 설정 적용 한거다
2.2 aws_s3_bucketlifecycle_configuration
lifecycle 적용이 필요한 terraform resource이다
2.3 aws 웹에서 봤을때 설정 결과 화면
웹에서 보면 아래와 같이 적용된 걸 확인 할수 있다(terraform 소스 적용한 결과)