Mysql Optimizer
사전지식 1. 옵티마이저
rdb는 sql질의문을 요청하면 해당 쿼리를 분석하여 최적의 실행 방법을 결정(어딜 어떻게 먼저 조회하고, 어떤 인덱스를 쓰고, 인덱스 타입은 이렇게 된다. -> 실행계획) 한 후, 그거 대로 실행한다. 그래서 적당히만 짜도 옵티마이저가 알아서 잘 분석하고 실행한다. 물론 최적의 인덱스 퍼포먼스를 보여줘야 한다면 그건 쫌 다른 이야기가 되버리는데, index랑 옵티마이저만 믿고 있다간 full scan or full index 이런거 걸려버리면 성능적으로 엄청난 문제가 생기긴 한다. 아무튼 요지는 테이블 순서나 where 조건절 순서 등에 관해선 옵티마이저 믿고 꽤나 자유롭게 짜도 별 상관이 없다.
사전지식 2. mysql 옵티마이저는 비용 기반으로 책정됨
옵티마이저는 규칙 기반 옵티마이저(rule based optimizer. 줄여서 rbo), 비용기반 옵티마이저(cost based optimizer. 줄여서 cbo) 2가지 종류가 있는데, 줄여서 설명하면 rbo는 그냥 룰이 무조건 정해져서 별다른 리소스 상태 같은건 무시하고 그 조건 내에서만 실행계획을 새워서 실행하고 cbo는 먼저 각을 재고(비용,리소스 계산. 어떻게 검색해야 더 좋을까, 드라이빙 테이블은 어떤걸 지정할까 등등) 실행계획을 새운다.
mysql을 포함해서 너무 오래된 버전이 아니라면 사실상 다 cbo를 쓰는데 방금 말한거 처럼 각 재고 실행을 한다는 점. 그니까 똑같은 쿼리문을 날려도 경우에 따라 실행 계획이 달라질 수 있다는 점이다.
이번 post에선 옵티마이저가 실행계획을 잘못 만드는 케이스를 소개&분석하는게 목적이다.
테스트용 테이블. 미리 말하면 이전 샘플용으로 만들어져 있는 테이블을 테스트용 테이블로 쓰고 있어서 스키마&관계 정보는 이해 부탁드립니다.
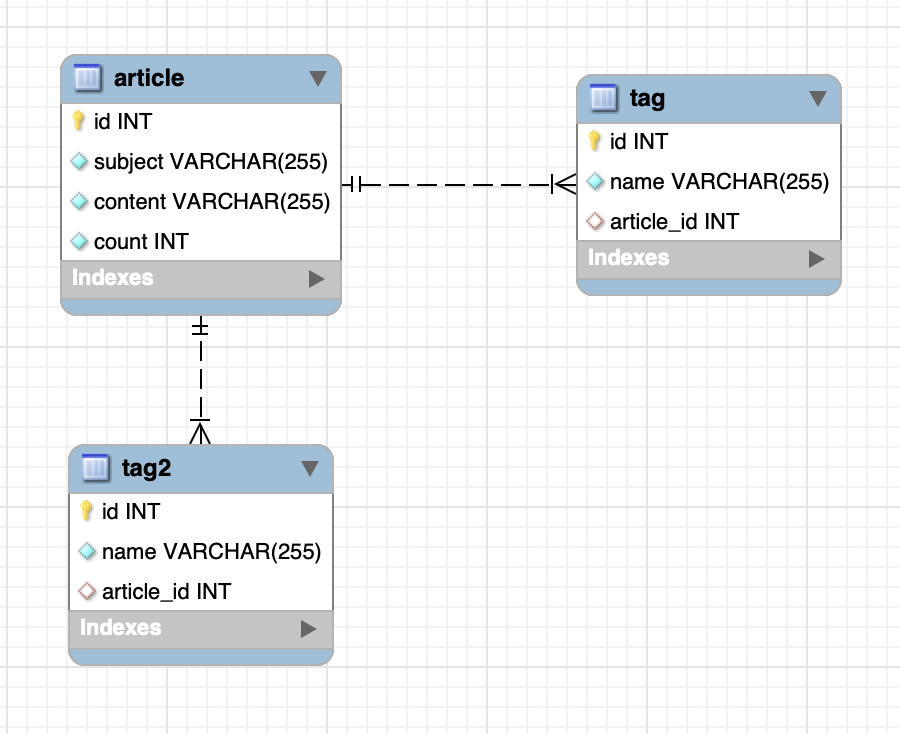
테이블 설명
article-> 그냥 테이블1. 테스트 환경을 기준으로 10만개 정도 데이터 row 가 있음tag-> article과 연관관계가 있고, fk를 같고있는 주체가 되는 테이블이며 1대1 관계로 관리 되고 있음. 15개 정도 데이터 row가 있음tag2-> tag 테이블이랑 다 똑같은데 데이터 row가 딱 1개만 있음
case 1. 위와 같은 상황에서 article&tag 테이블을 left join 하면?
select * from article
left join tag on tag.article_id = article.id
order by article.id
limit 10;그냥 정상적인 결과가 나온다. 실행 계획상에서도 전혀 문제가 없고, 실행되는 시간도 내 테스트 환경 기준으로 0.0019초 나온다.

case 2. 하지만 여기서 article&tag2 테이블을 left join 하면?
select * from article
left join tag2 on tag2.article_id = article.id
order by article.id
limit 10;엄청나게 느려진다. 실행 시간도 0.08초 ~ 0.152초로 대폭 증가한다(이 갭 관련해선 밑에서 설명). 다른 요소는 다 똑같은데 데이터가 많은 테이블을 조인하는건 빠르고 데이터가 적은 테이블을 조인 해서 결과를 얻는 것이 더 느리다는게 일반적으로 생각하면 말이 안된다.
mysql 5.7 버전으로 실행 계획을 확인해보면 아래와 같이 나온다

이런 결과가 나온건 내가 알기론 먼저 db조인을 할때 만약 테이블에 데이터가 얼마 없다면 옵티마이저가 모든 데이터와 조인 결과를 memory에 다 올려놓고 처리하는걸로 알고 있다. 근데 하필 left join 을 하면서 모든데이터를 올려놓다 보니 너무 데이터가 많아서 오히려 더 안좋은 실행계획이 세워지는 것으로 추측하고 있다
두번째 실행 계획에서 using join buffer(BNL) , Using temprary; Using filesort 이렇게 뜨는걸 보고 그렇게 추측하였다(row 개수가 적으면 모든 데이터를 불러 온 후, 핸들링 하는거 자체는 맞는 말이다).
이런 케이스는 일하면서 한번쯤은 만날 수 있는 경우라고 생각되는데 해결 방법으로는
- 그냥 조인 안씀(개인적으로 이거 추천)
- 가능하면 inner join으로 변경
- hint를 줘서 실행계획을 유도(딱히 추천하지는 않음. 해당 쿼리에 대해 관리비용이 더 들 수도 있다)
개발하면서 RDB라서 별 수 없긴 하지만 join이란건 생각보다 어플리케이션에 많은 문제를 발생시킬 수가 있다(대부분 의존관계 문제이다. 무분별하게 의존관계를 다 때려 넣는 짓은 하면 안된다) 이런 저런 이유로 생각 외로 join 안쓰면 많은 문제를 예방 하는 효과가 있긴하다.
만약 inner join 을 하게 되면 위와 같은 문제가 없어지고, 실행계획을 봐도 driving table 이 바뀌는거 말곤 딱히 특이한 점은 없다.
참고 사항으로 mysql 5.7 버전에선 BNL 조인이 되어버리지만 mysql 8.0이면 hash join으로 처리 해준다(8.0부터 지원 해주는걸로 알고 있다) 위에서 실행 시간 말할때 0.15초 정도 걸린 환경은 mysql 5.7 버전에서 BNL 조인 되면서 나온 속도이고 mysql 8.0으로 올리면 hash join 으로 개선되어 0.8초 정도 속도가 나오고 있다. 물론 0.8초도 엄청 느린거고 row 개수에 따라 더욱 느려질 것이므로 피해서 써야하는건 똑같다.

성능 측정 같은 경우엔 컴퓨터 성능에 따라 달라 질 수도 있다.
결론
- 옵티마이저는 똑똑하지만 항상 정확한 실행계획을 보장 해주는건 아니다.
- 모르겠다 생각 되면 그냥 실행계획 보자.